
RSS
Tim C. Taylor

Twitter: @timctaylor My hair's turned white since this photo. I blame having children :-) There's a beard too, but that defies explanation.
Latest novel release

Previous novel release

Learn about the Human Legion

Click here for my Human Legion site. Last I counted, I'd sold over a quarter million copies. Pretty pleased about that!
Join the Legionaries and receive a free starter library

Most recent 4HU novel

My latest anthology

My recent anthology

Format YOUR Print Book

Fully illustrated. Kindle & paperback editions. I use this to produce my own books. See the 'Update March 2019' menu item in this website for updates.
Liebster Blog Award

I won an award!
Into the Polity and Beyond
Some fantastic new artwork from Vincent Sammy with Neal Asher’s new/old titles. I’m a big fan of Vincent’s work.
(If you’ve read my books, then you might recognize Vincent’s style as he’s done some great covers for some of my efforts).
Last year I had the amazing honor of being approached by Neal Asher to do the covers of his previously self published novellas and short stories. Needles to say , I jumped at the chance and immediately dove into this rich and amazing world that he has created.
The biggest problem for me was with the short stories – which one should I feature on the cover?!
In the end, I am very pleased with the result. All were originally drawn and painted in watercolor before moving on to digital post production. I’m rather proud of this collection.
Here are the first 4 covers. The last 2 will follow soon.














Posted in Uncategorized
Leave a comment
I host the SciFi Readers Club Chart Show
I’ve just started a sci fi chart show over at the FB group where I often hang out. Still figuring out how this is going to work and be fun for all without taking up too much of my time.
Here’s an intro and some images from the first entry to whet your appetite. The rest is over at SciFi Readers Club here.


“Down one place at #3 is Steve Wonder with Masterblaster. Randy Crawford is holding steady at #2 for one more day before she flies away. Which means we have a brand new #1. Straight into the top slot it’s The Police and Don’t Stand So Close to Me.” [Roll music video.….]
I used to love the music chart shows when I was younger. It was like supporting team sports in some ways. I’d root for my favorite artists to chart well, have a good-hearted moan when a song outstayed its welcome at the top, and be introduced to artists I wouldn’t otherwise have discovered. All while enjoying fun contemporary music culture.
So I wondered: why not do something similar for science fiction book charts?
Possibly, this fixation in my head is a British thing from a now bygone era.
When I was younger, a large proportion of people of my generation would tune into the BBC Radio One or BBC 1 on the telly for Thursday night’s Top of the Pops. This was a live top-40 singles chart rundown show with selected acts playing live in the studio.
In those days, there were only two main TV channels (with a third for obscure stuff… that I tended to love), so audience numbers for popular shows were huge. The next morning at school, everyone would be talking about last night’s show. These memories embed strongly and still resonate decades later.
Once at university or working your first job and living in a tiny flat, we discovered that the simultaneous radio broadcast through the Hi-Fi was best enjoyed with good company and beer.
So I wondered whether I could have a laugh and do a regular little chart rundown slot for science fiction book charts. Just for fun and to get people talking about books. Since it’s a chattier place than my blog, I’m going to do this on the SciFi Readers Club Facebook page.
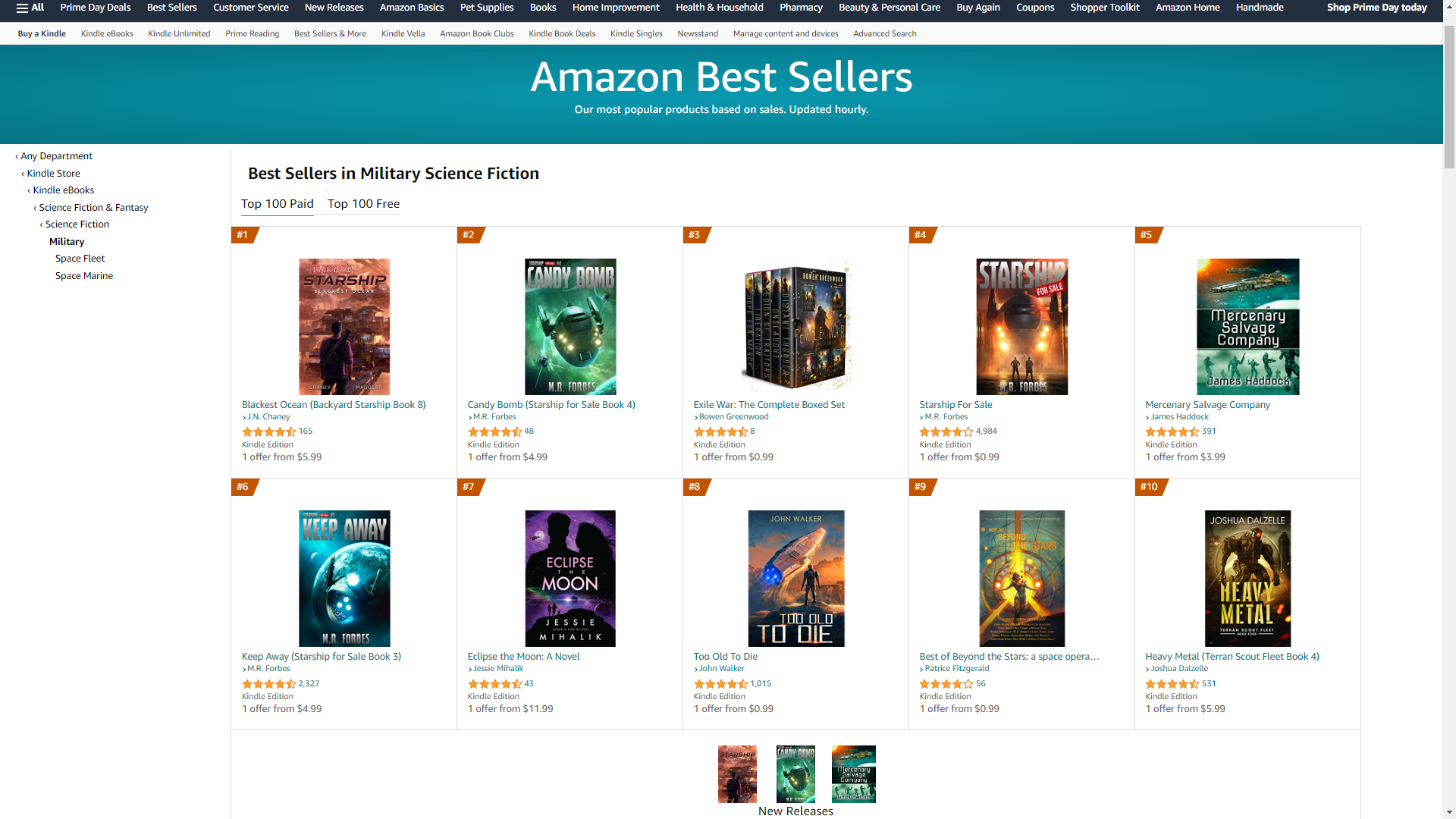
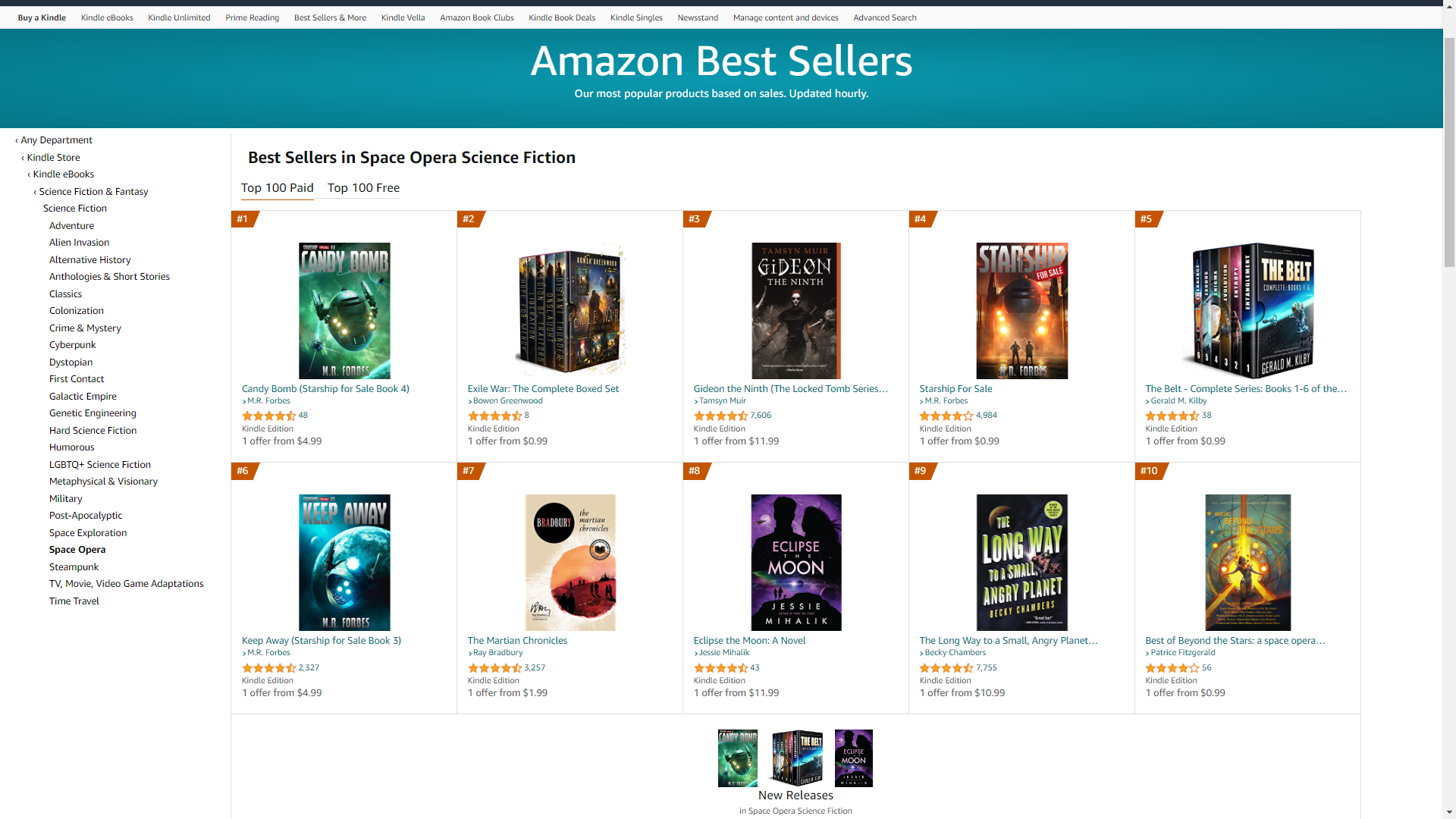
I’m not certain how this is going to work, which means we’ll just have to work out the details as we go along… just like so many of our favorite science fiction characters. To being with, I’ll take the two charts on amazon.com of most interest to the club: military science fiction and space opera. I’ll do the following:
- a quick rundown of trends and new entries in the top 50s.
- List the top books. (just for space opera for the time being)
- Pick one book that takes my interest. Probably read it too.
- And do anything else I fancy. There are no limits.
Join in the fun. Let me know what you think. And hopefully we’ll make this a bit of fun.
Tim
Me and Multiple Sclerosis
I posted an update on social media last week; I’ve copied it below. Basically, I’m fairly sure I have multiple sclerosis, but I’ll have to wait until next year for a formal diagnosis. I’m posting things like this because if I’ve said publicly what’s happening to me, then it’s more difficult for me to pretend nothing’s wrong and do nothing about it.
Cheers,
Tim
There’s something I’ve been meaning to get off my chest for a while, and it is affecting my work and my dealings with friends, colleagues and family.
I haven’t been quite myself for the last couple of years. So I went to see a doctor. Had an MRI scan. And the conclusion is… nothing. At least, not yet.
I have an appointment to see a neurologist next year and I won’t get a diagnosis until then.
Which leaves me in an inconvenient limbo state.
Because I do know the MRI scan showed demyelination of my brain and spinal cord. Demyelination is the cause of multiple sclerosis, and the reason I was sent for an MRI scan is because I tick many of the boxes for multiple sclerosis symptoms. I have subsequently ticked several more.
There are other reasons why I might have demyelination and a multiple sclerosis diagnosis is a complex thing. So I might not have MS at all. However, having looked into this, MS seems the hot favourite for explaining why I haven’t been well.
I have over seven months to wait until I see the neurologist. I decided at the beginning of this week that seven months is too long a time to continue living my life in a way that’s no longer working for me.
So I’ve decided to make a working assumption that I do have MS and act accordingly. If the neurologist says differently, then I’ll react to what they say when we get there.
I finished a novel yesterday (Time Dogz #2), which makes now a perfect time to take a few days off to rethink and retool my days. I want to get the most out of what I can do rather than carry on in ways that no longer work.
And that does leave a great deal I can still do. I’m beginning to run again after a long enforced break. I’ve also written one and a half novels this year so far and work less in the evenings and weekends. But now I understand my situation more clearly, I can do better on all those things, do it in a less tiring way, and leave more time to relax with family, friends, and hobbies.
All I need is a rethink and to adapt my approach to a lot of things.
A few people have noticed I’ve been quiet or distant for patches of time, especially on social media. Now I begin to understand that the explanation is likely neurological. Some tasks I used to do without thinking can be exhausting sometimes, even though I enjoy them. At times, that includes chatting away on Facebook. It still doesn’t really make sense, but there you go. I’m sure I’ll work it out.
Anyway, that’s your lot. This is not an Otto Sump Sob Story because it’s just me requiring a little adjustment. I just wanted to keep everyone up to speed.
Cheers.

Posted in Multiple Sclerosis
5 Comments
Karnage Zax. Mutant Bounty Hunter
I had a new book release yesterday, which you might like to try. This is an anthology called We Dare: Wanted, Dead or Alive. Inside is my new novelette, FRAkkers
I love a themed anthology and this one is about bounty hunters and the hunted. Most authors went for the hunted, but not me. Not sure what that says about my psyche, but let’s not dwell on that and instead focus on my new anti-hero.
Karnage Zax is a mutant bounty hunter with pre-cog abilities. Together with Itka Jowiszka, his cyborg sidekick, he knows how to move among the scum of the galaxy because he’s one with them.
The hunter and the hunted. Sometimes it’s tricky to tell which is which.
If you enjoy reading about Karnage and Itka, let me know because I might write some more! In fact, I’m musing over whether to write an Itka companion piece later this month.
Strontium Dog inspired. Yes, definitely! [If you don’t know Johnny Alpha, go here]
(Edited to add: I’ve written a follow-up story that swaps hero and protagonist to feature Itka instead. Will be coming to an anthology late 2022 or early 2023)

Titans Rising: a personal journey from 1937 to 2022
My latest book, out today, has its genesis in books by other writers published 52 years apart (or perhaps 73, as we shall see).
One is a personal improvement book written in 1937 that has sold 15 million copies and is still frequently referenced today. The other was a survey of the British science fiction and fantasy writing establishment in 1989.
Combine the two and you get my contribution to today’s book launch: Titans Rising: The Business of Writing Science Fiction, Fantasy, and Horror in the 21st Century, published by Quillcraft Press.

The publisher doesn’t know anything about that 1989 contribution, so let’s start in the America of 1937 with Think and Grow Rich by Napoleon Hill. The premise was to collect the reflections of successful entrepreneurs and attempt to distil the essential behaviors and attitudes that made them successful. By applying these learnings, readers would find greater success in their own lives. And not just in business; this extended to all aspects of life.
When I’m running, I sometimes listen to motivational audiobooks and that Napoleon Hill book and its findings are still frequently referenced. I would love to think that any of my writing would be read and discussed in 85 years’ time.
Titan’s Rising takes some of the most successful indie and small press authors in the arena of science fiction, fantasy, and horror, and seeks to distil what it is about them that makes them so successful. Like Hill’s 1937 classic, Titan’s Rising aims to do so in a way that will help authors (and publishers) to greater success in their own endeavors.
I haven’t read the book yet. My copy should arrive tomorrow and I’m eager to read. I’m eager to learn too. Just because I am one of the contributors, doesn’t mean I’m not part of the audience to read this book. In fact, I expect to learn a great deal from the other writers.
And what a lineup they are!
You can imagine the publisher for a book like this describing its contributors as ‘some of the leading authors of science fiction, fantasy, and horror today’. In the case of Titan’s Rising, this hype would be justified. In the indie and small press world, these really are some of the most successful authors around. I’ve been writing and publishing science fiction and fantasy as a full-time career for eleven years now, and on this at least, I know what I’m talking about. There is premier quality talent here.
So much so that I feel very much one of the most junior contributors. Nonetheless, I believe I have made suggestions that I feel sure will help some readers.
So what about 1989?

I used to belong to an organization called the BSFA (British Science Fiction Association). Alongside sister organization the British Fantasy Society, this was essentially the establishment for British SF/F/H fans and traditionally published authors and the small press as it was then.
The BSFA ran an author survey in 1989 and then again in 2009. A few years later, members received a paperback (by Paul Kincaid and Niall Harrison) that condensed the responses from both surveys and tried to draw conclusions about how things had changed over those twenty years.
To be honest, there weren’t clear conclusions about anything very much. Nonetheless, I still found this a fascinating read. By the time I received the book, I was a professional science fiction writer myself, and as I read the responses of other authors to the survey questions, I naturally wondered how I would have responded.
That BSFA book was originally published in 2010, which was the year when science fiction publishing changed fundamentally with the introduction of Amazon Kindle Direct Publishing. I’m sure many (most?) professional science fiction and fantasy writers of today would scratch their heads when reading that 2010 book, because it represents an alternative view of publishing, one that still exists but is very different from most of our experiences.
1989. 2009. 2029.
I have half a sleeper ear, primed to activate in seven years and listen out for a sequel.
Seven years! Doesn’t sound so impossibly distant now.
If that does come about, and if I were invited to contribute (for which there is a minuscule likelihood), then you would have to wait at least another eight years before such a book could be published.
Now you don’t have to.
Today, I present Titan’s Rising. Compared with the BSFA publication, it has a much greater emphasis on teaching how to succeed and in selecting contributors who are themselves commercially successful. Whether or not that’s a good thing depends upon your perspective. But for me, in addition for the publisher’s stated purpose, Titan’s Rising should make a fascinating counterpoint to the BSFA book.
As I write these words, I haven’t yet read Titan’s Rising, but I do know the other contributors, their reputations, and their success. I don’t need to read it to know that anyone serious about succeeding in the world of indie and small press publishing, or simply interested in the state of publishing today, will find buying, reading, and digesting this book to be one of the best investments you can make this year.
I’m sure you can pick up a copy at the FantaSci convention that’s kicking of as I write this post. Hi to everyone at FantaSci! For anyone not in Durham, NC this weekend, you can grab a copy from Amazon USA | UK | CA | OZ | DE

Tim C Taylor is lucky enough to write science fiction adventure for a living.
His most recent book is the anthology, You Pay; We Slay, by Hit World Press.
I write short stories too!
Yesterday was the launch of the first Hit World anthology, You Pay; We Slay. It contains the first story I’ve written for nearly twenty years that isn’t overtly science fiction or fantasy.
By weird coincidence, I received paperback editions of You Pay; We Slay and my previous two anthologies across three consecutive days. Something struck me: my name was on the cover of all three.

Blagging your name on the cover of an anthology or magazine is something to be proud of. It (usually) means the publisher thinks your name shifts copies.
I was pretty chuffed about this, because I see writing short fiction primarily as fun. It stretches my writing muscles and I do use it to explore new ideas and new ways of telling them, but it’s with novels that I earn the money to put a roof over our heads.
Writing novels is my job. Short fiction, not so much.

I did a stock count and can come up with seventeen anthologies I can remember that contained my stories, with three more due in 2022. Seven of those featured my name on the cover.
I rate sixteen of those anthologies as being strong. There’s only one where I felt several of the other stories were weak, but even there I’ll happily accept that the authors are highly regarded, but not to my taste. Plus it had my favourite cover of all my anthologies, so it sits proudly on my bookshelf.
Maybe I’m more of a successful short story writer than I thought.
I totted up a rough average of how much I’d earned from those seventeen anthologies and came up with 13c per word. That’s definitely a professional pay rate.
But, hold on! That 13c is the mean. With around half of those anthologies being a profit share, the financial return various enormously. For the median pay rate, I arrive at a semi-pro level of 2c per word.
I’m more comfortable with the 2c figure than 13c because that way the short fiction doesn’t feel like a job. I’m enormously fortunate that I write novels for a living, and I’m very comfortable with that.
Let anthologies remain a fun, artistic side hustle.
(But don’t stop paying me, publishers 😉 )

AMAHA – Ask Me And Him Anything
We had fun at an AMA last weekend hosted by audiobook reviewer (and listener!) Brian Krespen. The other person in the hotseat was Steve Campbell who was narrating Department 9, the third Chimera Company novel. (I say ‘was’ because he’s just finished).

I admit to being nervous with these sorts of things, but Brian did a great job and it turned out to be a lot of fun. You can find a recording of the AMA on Twitter (below) and Facebook.
Also, if you’ve been following my occasional ramblings on the publishing industry, you’ll have read me pointing out that many traditional publishers in the Anglo-American markets survived the pandemic year of 2020 with profits up, despite physical bookstores being closed at several points. Some of this was a rebound as readers rushed back to the stores, but most of it was due to a shift online.
Not that I want bookstores to close, but the stats were a blunt pointing out of what should be an obvious fact: physical bookstores need book publishers a whole lot more than publishers need bookstores.
So I was interested to read this article from the Bookseller stating that over two thirds of UK publishing revenue came from online channels in 2020.
I haven’t seen the report’s detail, so I can’t verify what they mean by ‘publishing’ in this instance. But I expect it to mean ‘trade publishing’. In other words, books from traditional publishing organizations that would until recently have been sold overwhelmingly through physical bookstores.
Note that this is revenue, rather than the publisher profits that I’ve been mentioning recently.
Things sold online tend to be cheaper. Also tradpub trade organizations love to complain that Amazon is screwing them on their margins*, and a big chunk of those online sales will be paperbacks sold through Amazon. Despite both these factors, profits were up as well as revenue. All of which seems to suggest that online sales through Amazon were very profitable in 2020**.
‘*’ They could be right about the margins, but distortion is so common in pro/anti Amazon positions that I just don’t know. Amazon takes a 40% margin on paperbacks when they retail my books.
‘**’ Being nice to suppliers is way down on the list of Amazon’s priorities, and they can and do change their rules to suit them. Just because tradpub selling print books through Amazon looks like a sustainable business model in 2020, doesn’t mean it will be in the future.
Posted in Uncategorized
Leave a comment
He Speaks!
My beard and I had a chat with Joe on the Unity 151 channel a few days ago. We discussed Chimera Company, On Deadly Ground, Time Dogz, knee injuries, Human Legion, foreign involvement in the Russian Civil War, audiobook narration, Salvage Title, Hit World and stamps of the early 20th century. ![]()
In other news round up, I’ve re-written and republished the two Reality War novels, Operation Redeal has come out in audio, and I’ve had three anthology releases since I last posted.
‘Monster at the Gate’ is my story from In The Wings, a 4HU anthology. A desperate human scavenger operation encounters an alien on a quest for meaning. Those who survive the exchange of views are changed forever.

‘Laney’s Logistics Ain’t Recruiting’ follows the experience of an alien work experience girl in the Salvage Title anthology It Takes All Kinds. It’s more fun that I can express in one sentence.

‘Time Dogz’ is in On Deadly Ground, a science fiction anthology of heroic last stands. There’s a definite anti-hero vibe as Stiletto Caldwell and team are sucked into humanity’s last defense at the space battle of Saturn’s Gate. I liked it so much, I’m writing the novel now.

I’ve stories in four more anthologies due out early next year.
That is… they’ll come out if I actually write the things. I’d better get back to work… 😉
Posted in Announcements
Tagged Chimera Company, hit world, Human Legion, interview, salvage title, Unity 151
Leave a comment




Amazon eBook Return Controversy
There’s a fuss smouldering away in some parts of the author community, especially the parts that primarily sell Kindle eBooks through Amazon. In a nutshell, Amazon has a lax eBook return policy and some readers are abusing it by reading books they have no intention of paying for.
That much is… well, it’s debatable whether even that much is entirely true*, but we’ll say it is for the moment.
For some authors, this trend has led to a surge in returns. That sucks. And it is hurting their bottom line.
That is true. And painful.
For most other authors this trend could lead to a permanent uptick in returns, but not one so dramatic that they’ve noticed.
That is plausible.
After that it gets messy really fast. There are conspiracy theories and disinformation that is clearly not true. Rumours are being claimed about Amazon charging authors for returns that are unsubstantiated by any evidence and that I find very difficult to believe.
The connecting thread for a lot of this is a hatred of Amazon. “Amazon is stealing from authors” is a claim frequently repeated. Often with a verb a whole lot saltier than ‘to steal’. Certainly, the villain of the piece has shifted away from people who buy and read books they have no intention of paying for and onto Amazon. It’s all Amazon’s fault.
There’s even a vituperative attack from the UK Society of Authors in which the literary worthies are so consumed by their hatred of Amazon that they direct their abuse at the wrong target*.
After a dozen years as a full-time writer, I can say from experience that this is just another day at the office. This kind of thing goes on all the time. In fact, this particular topic around Amazon eBook returns has been a recurring crisis in publishing since 2011. Hundreds of thousands of signatures have been collected over numerous petitions to make Amazon change its policy outside of Europe*.
My signature is included in several of those petitions, including the latest, here . I hope Amazon tightens up its return policy where it can. Personally, I don’t think it will because it’s too scared of falsely accusing customers who aren’t abusing the system, but I hope I’m wrong and it does try, because some authors and publishers are genuinely stung by returns abuse.
This may be an old story, but it bugs me because real people have been getting very upset about this topic. I’ve even seen some micro publishers remove their books from Amazon over this. Some have good reason to be upset, but many more do not because while we might criticise Amazon for the ease of abusing its return system, the real anger is coming from the conspiracy theory that Amazon is charging authors for returns.
What I know for certain is that Amazon isn’t charging me for returns. At least, not for the 7/14-day return window everyone’s talking about. They aren’t charging any other author I’ve talked to either. It’s possible they are charging specific unfortunates – I can’t rule that out without going through every individual’s royalty statements – but it does seem unlikely.
Until recently, I found it very easy to tell myself that a topic like this was not worth getting involved. Shut it out and ignore it.
Now it bugs me and distracts me from more important things. Like writing. I’m not sure whether this is connected with multiple sclerosis or this is advancing age revealing my destiny as Grandpa Simpson.
Whatever the reason, it’s been bugging me. So I produced a video of going through my royalty statements and my returns so that authors worried about the idea that Amazon charges them can go through their own figures and see what they’re really being charged. Or not being charged!
I hope it helps someone by putting their mind to rest. I’m certainly hoping it puts my mind to rest. To be honest, my plan is to do the video, write this post, and then permanently retire this topic from my head. However, if anyone wants to ask a question because they’re worried about this then fire away.
Here’s the video.
* Europe.
I keep mentioning Europe. The reason is that in October 2011, the European Union decided that Amazon’s ‘overly’ lax eBook return policy wasn’t, in fact, lax enough! So the EU issued a directive for all its member states to enact legislation to force Amazon (and every other online retailer) to adopt a 14-day no-questions-asked full refund window. Here in the UK, that EU directive is currently surfaced in the Consumer Rights Act (2015).
That’s why I say it’s not really Amazon’s return policy here in Europe. It isn’t. It’s the EU Commission’s policy. And like Judge Dredd, it’s the law.
(BTW: I’ve since learned a 7-day return window is also the law in Brazil. I did check for USA, Canada and Australia and believe that there are no state or federal laws forcing Amazon to use their 7-day return window policy. That’s still on Amazon.).
Share this: